Generative AI Fundamentals
Emergence of generative AI - due to huge investments in resources
Hiring a large team, spending on compute resources, and importantly, having the willingness to invest and develop big ideas, are all contributors to the rise of generative AI.
Foundation Models
Source: AWS Skill Builder
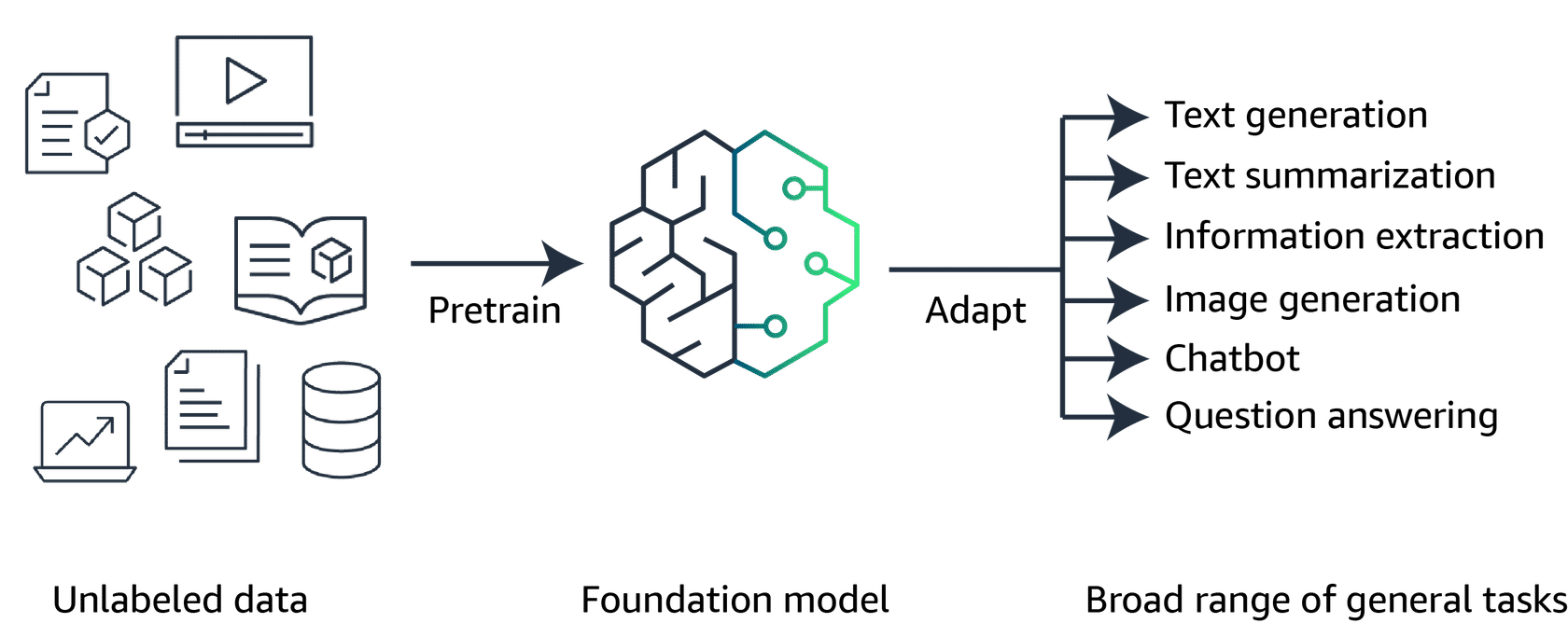
Generative AI is powered by models that are pretrained on internet-scale data, and these models are called “foundation models (FMs)”
With FMs, instead of gathering labeled data for each model and training multiple models as in traditional ML, you can adapt a single FM to perform multiple tasks.
These tasks include text generation, text summarization, information extraction, image generation, chatbot interactions, and question answering.
FMs can also serve as the starting point for developing more specialized models.
Foundation Model lifecycle:
- Data selection:
Unlabeled data can be used at scale for pre-training, easy to collect than labeled data.
FMs require training on massive datasets from diverse sources. -
Pre-training:
Although traditional ML models rely on supervised, unsupervised, or reinforcement learning patterns, FMs are typically pre-trained through self-supervised learning.
With self-supervised learning, labeled examples are not required. Self-supervised learning makes use of the structure within the data to autogenerate labels.During the initial pre-training stage, the FM’s algorithm can learn the meaning, context, and relationship of the words in the datasets. Like drink means bevarage(noun) or swalloing liquid(verb).
After the initial pre-training, the model can be further pre-trained on additional data. This is known as “continuous pre-training”.
- Optimization:
optimized through techniques like prompt engineering, retrieval-augmented generation (RAG), and fine-tuning on task-specific data. - Evaluation:
FM’s performance can be measured using appropriate metrics and benchmarks.
Evaluation of model performance and its ability to meet business needs is important. - Deployment:
deployed in the target production environment.
Deployment can involve integrating the model into applications, APIs, or other software systems. - Feedback and continuous improvement:
performance is continuously monitored, and feedback is collected from users, domain experts, or other stakeholders.
The feedback loop permits continuous enhancement of the foundation model through fine-tuning, continuous pre-training, or re-training, as needed.
Amazon Bedrock provides access to a choice of high-performing FMs from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon.
With these FMs as a foundation, you can further optimize their outputs with prompt engineering, fine-tuning, or RAG.
FMs that are essential to understanding generative AI’s capabilities
-
Large language models (LLM):
has variety of architecture, most common one is transformer architecture.
Transformer-based LLMs are powerful models that can understand and generate human-like text.
They are trained on vast amounts of text data from the internet, books, and other sources, and learn patterns and relationships between words and phrases.Tokens are the basic units of text that the model processes.
Tokens can be words, phrases, or individual characters like a period.
Tokens also provide standardization of input data, which makes it easier for the model to process.Embeddings are numerical representations of tokens, where each token is assigned a vector (a list of numbers) that captures its meaning and relationships with other tokens. These vectors are learned during the training process and allow the model to understand the context and nuances of language.
For example, the embedding vector for the token “cat” might be close to the vectors for “feline” and “kitten” in the embedding space, indicating that they are semantically related.LLMs use these tokens, embeddings, and vectors to understand and generate text. The models can capture complex relationships in language, so they can generate coherent and contextually appropriate text, answer questions, summarize information, and even engage in creative writing.
-
Diffusion models:
starts with pure noise or random data
models gradually add more and more meaningful information to this noise until they end up with a clear and coherent output, like an image or a piece of textForward diffusion: system gradually introduces a small amount of noise to an input image until only the noise is left over.
Reverse diffusion: noisy image is gradually introduced to denoising until a new image is generated.well-kown for text-to-image models
-
Multimodal models:
Instead of just relying on a single type of input or output, like text or images, multimodal models can process and generate multiple modes of data simultaneously.
For example, a multimodal model could take in an image and some text as input, and then generate a new image and a caption describing it as output.These kinds of models learn how different modalities like images and text are connected and can influence each other.
Multimodal models can be used for automating video captioning, creating graphics from text instructions, answering questions more intelligently by combining text and visual info, and even translating content while keeping relevant visuals.
Some generative models:
-
Generative adversarial networks (GANs):
involves two neural networks competing against each other in a zero-sum game framework. The two networks are generator and discriminator.- Generator: This network generates new synthetic data (for example, images, text, or audio) by taking random noise as input and transforming it into data that resembles the training data distribution.
- Discriminator: This network takes real data from the training set and synthetic data generated by the generator as input. Its goal is to distinguish between the real and generated data.
During training, the generator tries to generate data that can fool the discriminator into thinking it’s real, while the discriminator tries to correctly classify the real and generated data. This adversarial process continues until the generator produces data that is indistinguishable from the real data.
-
Variational autoencoders (VAEs):
combines ideas from autoencoders (a type of neural network) and variational inference (a technique from Bayesian statistics).- Encoder: This neural network takes the input data (for example, an image) and maps it to a lower-dimensional latent space, which captures the essential features of the data.
- Decoder: This neural network takes the latent representation from the encoder and generates a reconstruction of the original input data.
The key aspect of VAEs is that the latent space is encouraged to follow a specific probability distribution (usually a Gaussian distribution), which allows for generating new data by sampling from this latent space and passing the samples through the decoder.
Optimizing model outputs:
-
Prompt engineering: fastest and lowest cost option
Prompts act as instructions for foundation models. Prompt engineering focuses on developing, designing, and optimizing prompts to enhance the output of FMs for your needs. It gives you a way to guide the model’s behavior to the outcomes that you want to achieve.- Instructions: This is a task for the FM to do. It provides a task description or instruction for how the model should perform.
- Context: This is external information to guide the model.
- Input data: This is the input for which you want a response.
- Output indicator: This is the output type or format.
-
Fine-tuning:
Fine-tuning is a supervised learning process that involves taking a pre-trained model and adding specific, smaller datasets. Adding these narrower datasets modifies the weights of the data to better align with the task.- Instruction fine-tuning: uses examples of how the model should respond to a specific instruction. Prompt tuning is a type of instruction fine-tuning.
- Reinforcement learning from human feedback (RLHF): provides human feedback data, resulting in a model that is better aligned with human preferences.
Consider this use case for fine-tuning. If you are working on a task that requires industry knowledge, you can take a pre-trained model and fine-tune the model with industry data.
If the task involves medical research, for example, the pre-trained model can be fine-tuned with articles from medical journals to achieve more contextualized results. -
Retrieval-augmented generation (RAG):
Supplies domain-relevant data as context to produce responses based on that data.
This technique is similar to fine-tuning. However, rather than having to fine-tune an FM with a small set of labeled examples, RAG retrieves a small set of relevant documents and uses that to provide context to answer the user prompt.
RAG will not change the weights of the foundation model, whereas fine-tuning will change model weights.